Standard I/O
剛接觸程式的人(以前的我)可能會以為輸入跟輸出都是在混一塊的,因此看到題目上的 sample input 與 sample output 中是分開的,而且題目的排版方式又剛好是 input 在上 output 在下,可能會誤會成程式的結果要是讀完所有 input 後,再一次輸出所有 output。
例如:
假設現在有個程式叫做 add,其內容為簡單的加法,給予兩個整數作為 input,並將相加的結果作為 output 輸出。
1
2
3
4
5
$ ./add
1 2
3
3 4
7
一般我們看到的執行過程大概長這樣,看起來 input 跟 output 好像放在一起。所以,當題目的敘述為這樣:
1
2
3
4
5
6
7
Sample Input
1 2
3 4
Sample Output
3
7
可能誤會成程式的執行過程應該要長這樣:
1
2
3
4
5
$ ./add
1 2
3 4
3
7
但其實輸入與輸出是兩個不同的東西,雖然在螢幕上看好像混在一起,但實際上是分開的。就把它想像成兩個不同的檔案,一個叫做 input,程式會從裡面讀取資料,而另一個叫做 output,程式會將結果都寫在該檔案中。雖然說是想像,不過實際上也是這個樣子。
怎麼會說要把輸入與輸出想像成檔案呢?一般來說,我們都是由鍵盤輸入資料,並且由螢幕輸出結果。在一般我們使用的電腦上,鍵盤就稱作「標準輸入」,而螢幕則為「標準輸出」。注意,在其他裝置則不一定。在 C/C++ 裡面,標準輸入由 stdin 該變數表示,而標準輸出則由 stdout 表示。(另外還有標準錯誤輸出為 stderr,但不在我們討論的範疇內!)去查閱 stdio.h 的話,其實會發現 stdin 與 stdout 的資料型別為 FILE *,可以發現其實標準輸入與標準輸出都是以檔案操作的方式進行。如果熟悉 Unix-like 系統的人應該會更容易理解這一點,在 Unix-like 系統中有著「everything is a file」這樣的特性。
既然知道了輸入與輸出是分開的後,在寫程式時也不需要那麼辛苦的把所有輸出都存起來,最後再一次輸出至螢幕了。執行過程長這樣根本就是合法的:
1
2
3
4
5
$ ./add
1 2
3
3 4
7
File I/O
在 ACM-ICPC 的競賽中,大部份時候都是採用標準輸入與標準輸出。不過有時候也會有需要讀取檔案的時候,如需讀取檔案題目會特別告知。相信有寫過檔案讀寫的人應該都覺得有點麻煩吧!在比賽時,我們該怎麼讀取檔案會比較快速呢?
先來看看使用 C 的 fopen 的方法:
1
2
3
4
5
6
7
8
FILE *in = fopen(“inputfile”);
FILE *out =fopen(“outputfile”);
fscanf(in, ...);
fprintf(out, ...);
fclose(in);
fclose(out);
再來看看使用 C++ 的 fstream 的方法:
1
2
3
4
5
6
7
8
ifstream in = ifstream(“inputfile”);
ofstream out = ofstream(“outputfile”);
in >> x;
out << x;
in.close();
out.close();
其實好像跟原本差不多,不過就是多了開檔與關檔的動作!如果用的是 C 的 fopen 的話,那所有的 I/O 動作就要多打個 f,還要加上該檔案的檔案指標變數於參數中。如果使用 C++ 的 fstream,就真的只多開檔關檔,其他都一樣!但是,還有沒有更方便的方法呢?
答案就是 freopen,以下是其 pototype。
1
FILE * freopen ( const char * filename, const char * mode, FILE * stream );
使用方法很簡單,第一個參數填上要開啓的檔案名稱,第二個參數則是開啓的方式(例如:r 表示讀,w 表示寫),而第三個則是要將該檔案的內容重新導入哪一個檔案串流中。
因此只要利用以下這行,就可以將 input.txt 重新導入到標準輸入中,別忘了前面提到的,標準輸入的變數就是 stdin。
1
freopen( "input.txt", "r", stdin );
在程式最前面加上這行,所有檔案的內容都將可以透過 scanf、gets、getchar 等標準輸入的 function 來取得!
如果題目有要求要寫檔的話,只要將開啓模式改為寫入的模式(w),並將標準輸入的變數改為標準輸出的變數(stdout)即可,如下:
1
freopen( "output.txt", "w", stdout );
命令提示下的 I/O 導向
在練習題目時,想必大家都會不斷的測試自己的程式的正確性,也因此會大量的重複輸入測試資料。有些人會將測試資料複製起來,當程式執行時再貼上進行測試。然而我們其實可以將測試資料存到檔案中,並利用前文提到的 freopen 的方式進行測試,再也不用手動進行測試了!
不過,用 freopen 有個缺點,就是在 submit 時如果忘了把 freopen 拿掉的話,你就會得到一次 WA 或 RE 之類的,反正不會拿到 AC。所以,我們需要一個更方便的做法,也是這邊要說的 I/O 重新導向,這邊僅講簡單的 I/O 重導向,更進階的用法請自行 Google。
什麼是 I/O 重導向?就是把檔案的內容作為程式的「標準輸入」,或是把程式的「標準輸出」作為檔案的內容。直接來看做法吧!
假設有個檔案叫做 input.txt,而有支程式叫做 add,他接收來自「標準輸入」的資料,如同前面一樣,add 是一支讀兩個數字並相加輸出的程式。以下是 input.txt 的內容:
1
2
1 2
3 4
只要 < 符號,即可將 input.txt 作為 add 的標準輸入了,來看看執行過程:
1
2
3
$ ./add < input.txt
3
7
現在我們想要將輸出導向 output.txt 這個檔案中,只要將 < 改成 > 就可以了,執行過程如下:
1
2
3
$ ./add > output.txt
1 2
3 4
接著我們打開 output.txt 就可以發現裡面的內容為:
1
2
3
7
兩個也可以同時使用:
1
$ ./add < input.txt > output.txt
如此一來,打開 output.txt 就可以看到跟剛剛一樣的內容了!這是個非常實用的操作,而且非常簡單!其實也不用死背要用大於還小於,就把它當成箭頭來看,你想要資料從哪裡往哪裡跑!想從 a 到 b,那麼就把箭頭指向 b,反之亦然。另外,這個操作並不限於 Un*x 系統,在 Winodws 上也可以這樣操作!
多組測資與檔案結尾
ACM-ICPC 的題目絕大部份都是一次的測試中,會有非常多比測試資料,這代表著我們寫出來的程式要能進行連續輸入,並連續處理測試資料且輸出。從前面的例子就可以發現,測試資料中有兩組,一組是「1、2」,另一組是「3、4」。但讀取連續測試資料時,該怎麼停止呢?
有些題目會告訴我們讀到什麼樣的測試資料時,表示程式中止,而沒指定中止條件的則是判斷是否讀到「檔案結尾(EOF)」!以下是三種不同讀取資料的方式,以及其判斷 EOF 的方式:
scanf
1
2
3
while (scanf() != EOF) {
// do something
}
fgets
1
2
3
while (fgets() != NULL) {
// do something
}
cin
1
2
3
while (cin >> x) {
// do something
}
從程式碼應該很好理解,基本上就是 scanf 讀到 EOF 時,就會回傳 EOF 這個值回來(EOF 是一個 Macro)。而 fgets 的話,在讀到 EOF 時,因為讀不到東西了,即回傳 NULL 回來。最後是 cin,cin 的回傳值為 istream 類型,遇上真假值判斷時,會依照物件狀態決定回傳的真假值。所以,當 cin 讀到 EOF 時,cin 內部會有 EOF 的狀態,此時 istream 在回傳時就會傳回 false。
此外,EOF 其直通常是 -1,所以有時候可能會看到有以下的寫法:
1
2
3
while (~scanf()) {
// do something
}
由於 EOF 其值為 -1,而 -1 用位元表示為 111…111。因此透過 not 位元運算(~),則會變成 000…000,其值也等於 0,在大部份環境中,0 也代表著 false!所以可以利用這樣簡短的寫法來實現讀到 EOF 停止!
如果題目有指定終止條件的話,也可以將該條件寫在 while 迴圈內。以前面的相加程式為例,假設規定當輸入的兩個整數都為 0 時終止程式,就可以利用以下的寫法:
1
2
3
while (~scanf("%d %d", &a, &b) && (a || b)) {
// do something
}
題目通常還有一種,就是會在開頭就告訴我們接下來會有幾筆測試資料,例如以下這個 input.txt 檔案,一開始就告訴我們測試資料會有 2 筆:
1
2
3
2
1 2
3 4
面對這樣的測試資料,可以採用以下兩種寫法,且適用於不同情況。若題目的輸出,有包含當前測試資料的編號,則採用以下這種:
1
2
3
4
5
6
int test;
scanf("%d", &test);
for (int t = 0; t < test; ++t) {
// do something
printf("#%d …", t);
}
若題目沒要求輸出測資編號,我個人比較推薦以下這種,寫起來較省時,在比賽中時間很珍貴的:
1
2
3
4
5
int t;
scanf("%d", &t);
while (t--) {
// do something
}
讀取一行
在某些情況下,我們可能會需要讀取一整行的資料,原因可能是:
- 包含空格
- 無法確定資料數量
- 讀取字串
在 C 裡面,可以利用 gets 或 fgets 來完成,不過 gets 這個 function 有些危險,使用的話編譯器會跳出「警告」,但其實還是可以用就是了。以下是 gets 與 fgets 的範例:
gets
1
2
3
4
char buf[100];
while (gets(buf)) {
// do something
}
gets 會讀取一整行直到讀到換行字元(\n)或是檔案結尾(EOF)。要注意的是,gets 讀出來的結果,並不會包括換行字元(\n),也就是說在輸入緩衝區中仍保有換行字元!
假設上面那段程式中,do something 的部分都不再有任何讀取資料的動作,如此一來可能會發生問題。在處理完第一次的 gets 後,下一次執行 gets 時,僅會讀到一個換行字元(\n),這時候在進行運算時可能就會發生錯誤,甚至是 runtime error。因此,通常我在使用 gets 之後,會再加上一行 gets() 或是 getchar() 來去掉緩衝區內的換行字元(\n)。
fgets
1
2
3
4
char buf[100];
while (fgets(buf, sizeof(buf), stdin)) {
// do something
}
fgets 與 gets 不同的是,fgets 會檢查長度,最多只會讀取(第二個參數的值 - 1)這麼大的資料。因此不會因為資料過多而造成記憶體錯誤,這也是 gets 危險的地方。另外跟 gets 一樣,讀取到換行字元(\n)或檔案結尾(EOF)後停止。但要注意,fgets 若是因為讀到換行而停止的話,讀取出來的結果會包含換行字元(\n),在處理字串時一定要特別注意!不過也因此不需要像 gets 一樣,還要將緩衝區內的換行字元讀出來。
而 C++ 的部分可以利用,cin.getline 或是 getline 來達到。直接來看範例:
cin.getline
1
2
char buf[100];
cin.getline(buf, sizeof( buf ), '\n');
cin.getline 要傳入一個 C-style 的字串,另外要指定長度。而最後一個參數則非必要,該參數用來指定停止的字元,也就是讀到該字元的話,將停止輸入。當最後一個參數未指定時,則預設採用換行字元(\n)。
getline
1
2
string buf;
getline(cin, str, '\n');
getline 與 cin.getline 是不一樣的,我個人認為這個比較好用。第一個參數為 input 來源,若使用標準輸入的話,則填入 cin。第二個參數則需傳入一個 STL 的 string 物件,用來儲存讀取到的內容。第三個參數如同 cin.getline 的一樣,也是非必用的參數,用來指定停止的字元,未指定則預設為換行字元(\n)。
I/O 效率
其實 I/O 效率在程式的執行過程中,算是非常慢的!現今的 CPU 速度都非常快,在計算資料上除非演算法超爛,否則通常不是問題,當演算法正確時,效能瓶頸可能就是在 I/O 了。
這邊我們要討論不同的 I/O function 的效率。首先先來看到 scanf/printf 與 cin/cout 的比較:
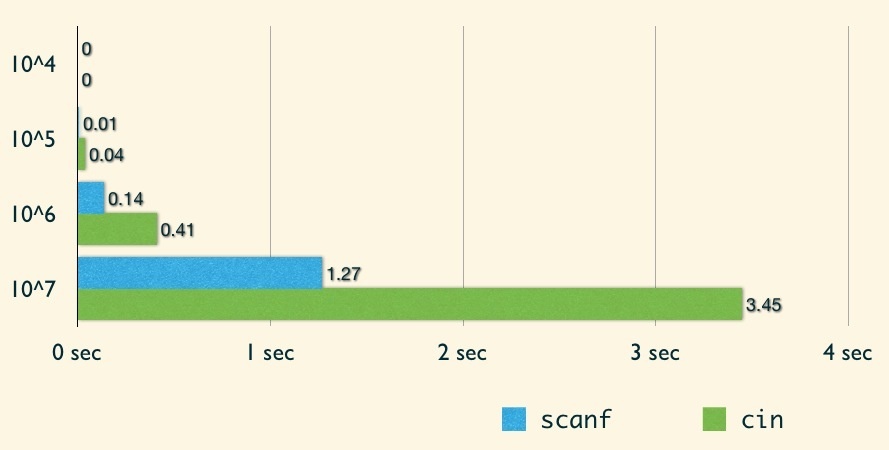
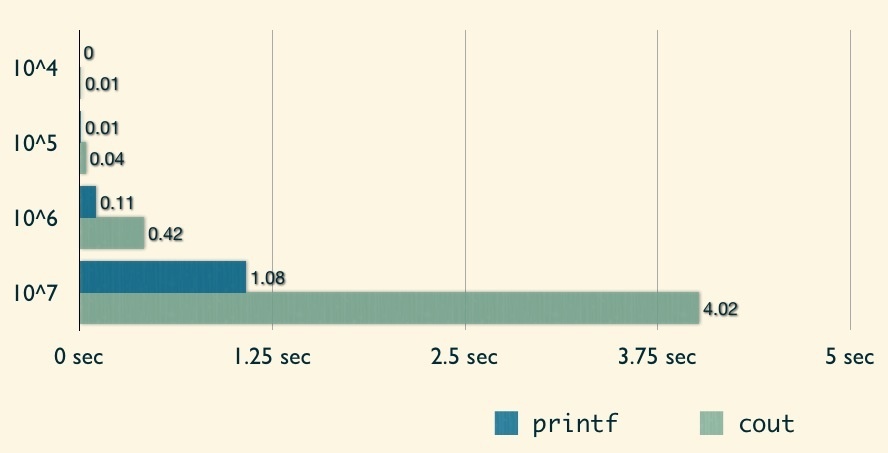
從圖中可以發現 cin/cout 的效率實在輸 scanf/printf,因此建議比賽時還是使用 C 的 I/O 會比較合適!
另外,是什麼原因造成 cin/cout 如此緩慢?!找了些資料發現其中一個原因是,cin/cout 每次都必須要與 C 的 I/O(scanf/printf 等)進行同步,以免兩邊讀取的資料不相同等問題發生!
因此,當我們要寫的程式中「僅」會使用到 cin/cout,完全不會使用到 C 的 I/O 時,我們可以在程式碼中加入以下這行:
1
std::ios::sync_with_stdio(false);
加入這行後,我們再來看看 C++ 的 stream I/O 的效能:
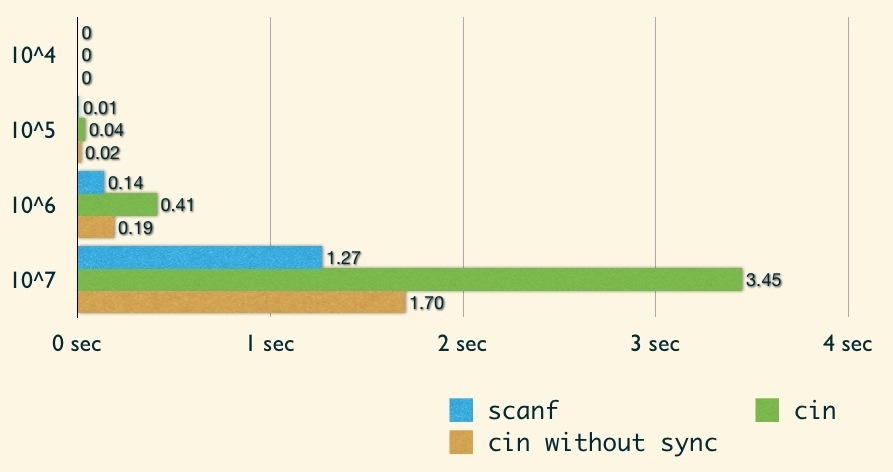
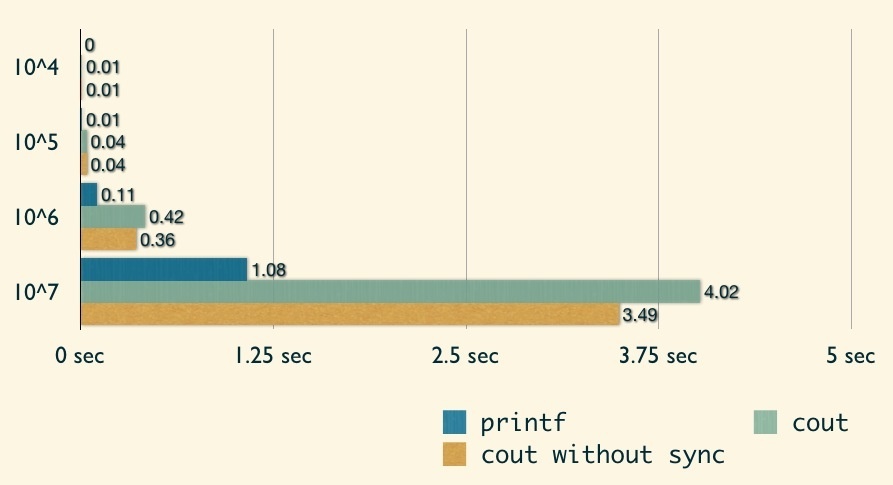
可以發現在 cin 上,有著顯著的改進,不過 cout 的改進幅度就較差了點。但很明顯的,scanf/printf 仍舊佔有著最快的寶座。因此在參加 ACM-ICPC 競賽時,建議還是使用 C 的 I/O!而且我個人覺得 C++ 的 stream I/O 排版實在很不方便!
不過很少題目會因為 scanf/printf 與 cin/cout 的效率而導致 TLE 就是了,但不代表沒有。基本上還是在大量資料時,才會有顯著的差異!
Buffered Technique
前面提到 I/O 其實很慢,除了把 cin/cout 都改用 scanf/printf 外,還可以在加速嗎?答案就是利用緩衝區,由於 I/O 很慢,那麼我們就先把資料暫存在記憶體中,讀寫時就以較大的區塊來進行,如此一來即可減少 I/O 的次數,也因此達到加速的效果。
首先先來講讀取資料的部分,我是把它稱作 「buffered read」,若有更好的名詞也麻煩推薦給我一下!這邊在讀取時主要是利用 fgets 這個 function,利用 fgets 即可一次讀取較大的資料進來。由於讀取的資料是一個較大的區塊,對於其內容並沒有進行過處理,所以接下來的步驟就是進行資料的 parsing。一個最簡單的方式就是利用 sscanf,如同 scanf 的使用方式,差別在於它的資料來源是「字串」。因此我們就可以從剛剛用 fgets 讀到的字串中的不同資料給分隔出來,以下是讀取兩個數字的範例:
1
2
3
4
5
char buf[1000];
int a, b;
fgets(buf, sizeof(buf), stdin);
sscanf(buf, “%d %d”, &a, &b);
// do something
要注意的是,輸入測試資料時,該兩個數字需要放置在同一行,不可隔行!
接下來是資料寫入的部分,也就是「buffered write」。這次利用 puts 這個 function,這是一個可以直接將字串輸出的函式。做法就是先將要輸出的資料放置於字串內,這邊可以利用 sprintf,一樣是個與 printf 相似的 function,只不過對向改成「字串」而已。當字串完成後,在利用 puts 進行輸出,即可有效減少許多 I/O 的次數了!以下是輸出一個整數的範例:
1
2
3
4
char buf[1000];
int ret = 10;
sprintf(buf, “%d”, ret);
puts(buf);
接下來來看效能比較表:
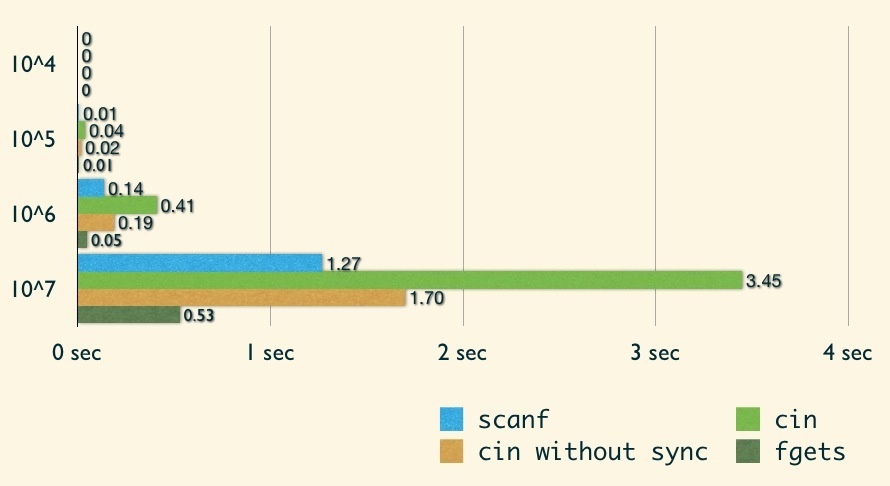
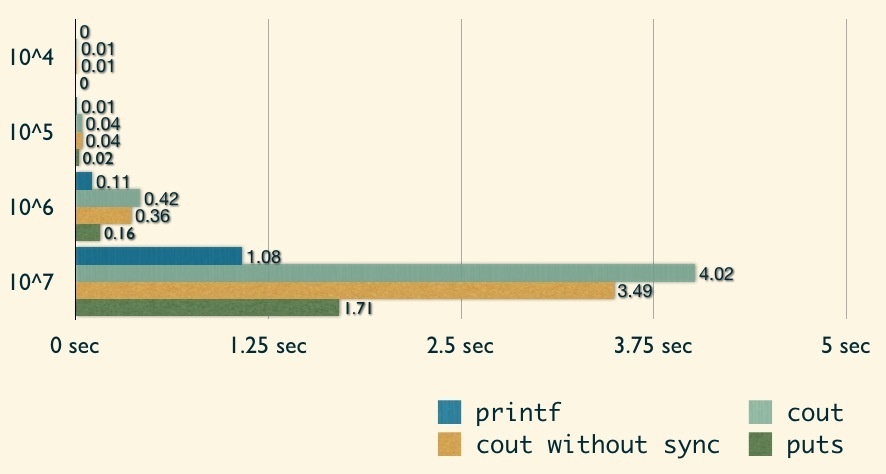
可以發現緩衝區的技巧,可以大幅增進 I/O 的效率!但在 puts 的部分可能會發現效能比 printf 還差,我認為應該是我的範例僅輸出一個整數而已,非但沒有減少 I/O 次數外,還多花了將資料寫到字串的時間。一般這個技巧不會僅用來輸出單比測試資料,會將每次的結果都寫到字串內,最後再一次性地輸出,才是真正有效減少 I/O 的技巧!
從 puts 的效率較差可以發現,其實 I/O 的效能還是要看輸出的資料內容,不同的內容會有不同的 I/O 方法!
編修紀錄
- 2013/04/06: 手殘將
while (~scanf("%d %d", &a, &b) && (a || b))打為while (~scanf("%d %d", &a, &b) && a && b),使得條件變為任意數值為零則跳出 while 迴圈。